Microsoft DP-203 Real Exam Questions
The questions for DP-203 were last updated at Apr 01,2025.
- Exam Code: DP-203
- Exam Name: Data Engineering on Microsoft Azure
- Certification Provider: Microsoft
- Latest update: Apr 01,2025
You have an Azure Synapse workspace named MyWorkspace that contains an Apache Spark database named mytestdb.
You run the following command in an Azure Synapse Analytics Spark pool in MyWorkspace.
CREATE TABLE mytestdb.myParquetTable(
EmployeeID int,
EmployeeName string,
EmployeeStartDate date)
USING Parquet
You then use Spark to insert a row into mytestdb.myParquetTable.
The row contains the following data.

One minute later, you execute the following query from a serverless SQL pool in MyWorkspace.
SELECT EmployeeID
FROM mytestdb.dbo.myParquetTable
WHERE name = ‘Alice’;
What will be returned by the query?
- A . 24
- B . an error
- C . a null value
You have an Azure Databricks workspace named workspace1 in the Standard pricing tier.
You need to configure workspace1 to support autoscaling all-purpose clusters.
The solution must meet the following requirements:
✑ Automatically scale down workers when the cluster is underutilized for three minutes.
✑ Minimize the time it takes to scale to the maximum number of workers.
✑ Minimize costs.
What should you do first?
- A . Enable container services for workspace1.
- B . Upgrade workspace1 to the Premium pricing tier.
- C . Set Cluster Mode to High Concurrency.
- D . Create a cluster policy in workspace1.
HOTSPOT
You are designing a monitoring solution for a fleet of 500 vehicles. Each vehicle has a GPS tracking device that sends data to an Azure event hub once per minute.
You have a CSV file in an Azure Data Lake Storage Gen2 container. The file maintains the expected geographical area in which each vehicle should be.
You need to ensure that when a GPS position is outside the expected area, a message is added to another event hub for processing within 30 seconds. The solution must minimize cost.
What should you include in the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


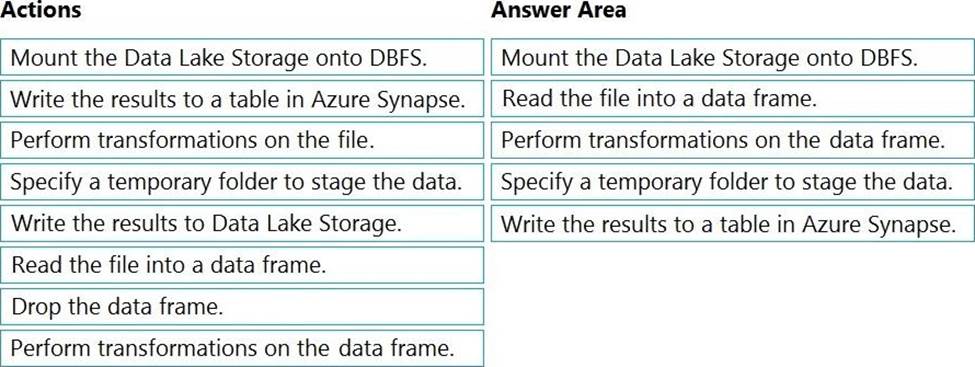
DRAG DROP
You have an Azure Data Lake Storage Gen2 account that contains a JSON file for customers. The file contains two attributes named FirstName and LastName.
You need to copy the data from the JSON file to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values.
You create the following components:
✑ A destination table in Azure Synapse
✑ An Azure Blob storage container
✑ A service principal
Which five actions should you perform in sequence next in is Databricks notebook? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You are designing an Azure Stream Analytics job to process incoming events from sensors in retail environments.
You need to process the events to produce a running average of shopper counts during the previous
15 minutes, calculated at five-minute intervals.
Which type of window should you use?
- A . snapshot
- B . tumbling
- C . hopping
- D . sliding

You have an Azure Stream Analytics job that receives clickstream data from an Azure event hub. You need to define a query in the Stream Analytics job.
The query must meet the following requirements:
✑ Count the number of clicks within each 10-second window based on the country of a visitor.
✑ Ensure that each click is NOT counted more than once.
How should you define the Query?
- A . SELECT Country, Avg(*) AS Average
FROM ClickStream TIMESTAMP BY CreatedAt
GROUP BY Country, SlidingWindow(second, 10) - B . SELECT Country, Count(*) AS Count
FROM ClickStream TIMESTAMP BY CreatedAt
GROUP BY Country, TumblingWindow(second, 10) - C . SELECT Country, Avg(*) AS Average
FROM ClickStream TIMESTAMP BY CreatedAt
GROUP BY Country, HoppingWindow(second, 10, 2) - D . SELECT Country, Count(*) AS Count
FROM ClickStream TIMESTAMP BY CreatedAt
GROUP BY Country, SessionWindow(second, 5, 10)
You are designing an Azure Databricks interactive cluster. The cluster will be used infrequently and will be configured for auto-termination.
You need to ensure that the cluster configuration is retained indefinitely after the cluster is terminated. The solution must minimize costs.
What should you do?
- A . Clone the cluster after it is terminated.
- B . Terminate the cluster manually when processing completes.
- C . Create an Azure runbook that starts the cluster every 90 days.
- D . Pin the cluster.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text and numerical values. 75% of the rows contain description data that has an average length of 1.1 MB. You plan to copy the data from the storage account to an Azure SQL data warehouse.
You need to prepare the files to ensure that the data copies quickly.
Solution: You modify the files to ensure that each row is more than 1 MB.
Does this meet the goal?
- A . Yes
- B . No
You have an Azure Synapse Analystics dedicated SQL pool that contains a table named Contacts.
Contacts contains a column named Phone.
You need to ensure that users in a specific role only see the last four digits of a phone number when querying the Phone column.
What should you include in the solution?
- A . a default value
- B . dynamic data masking
- C . row-level security (RLS)
- D . column encryption
- E . table partitions
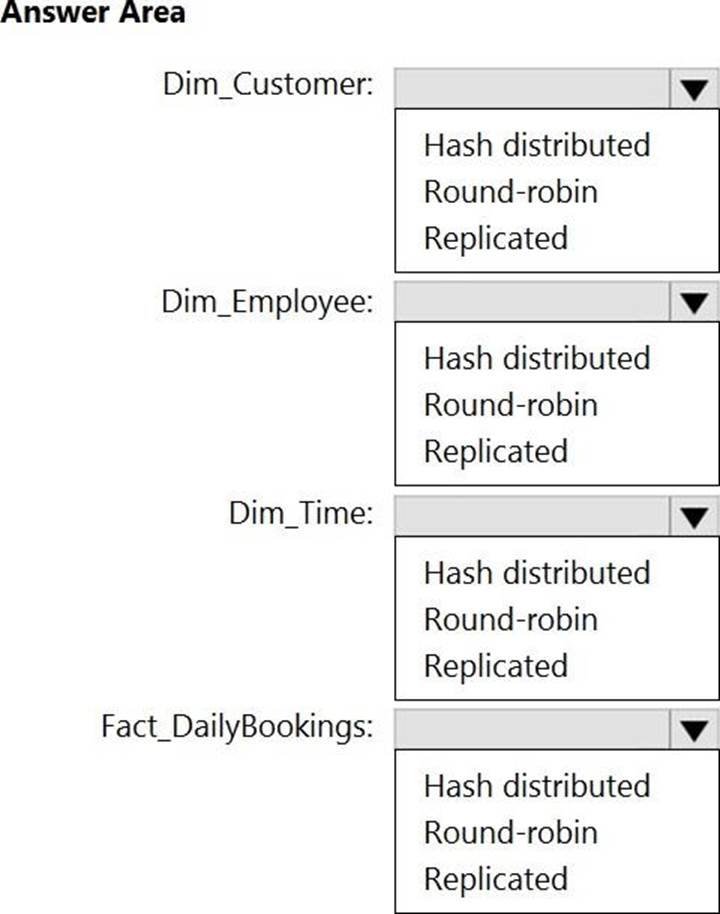
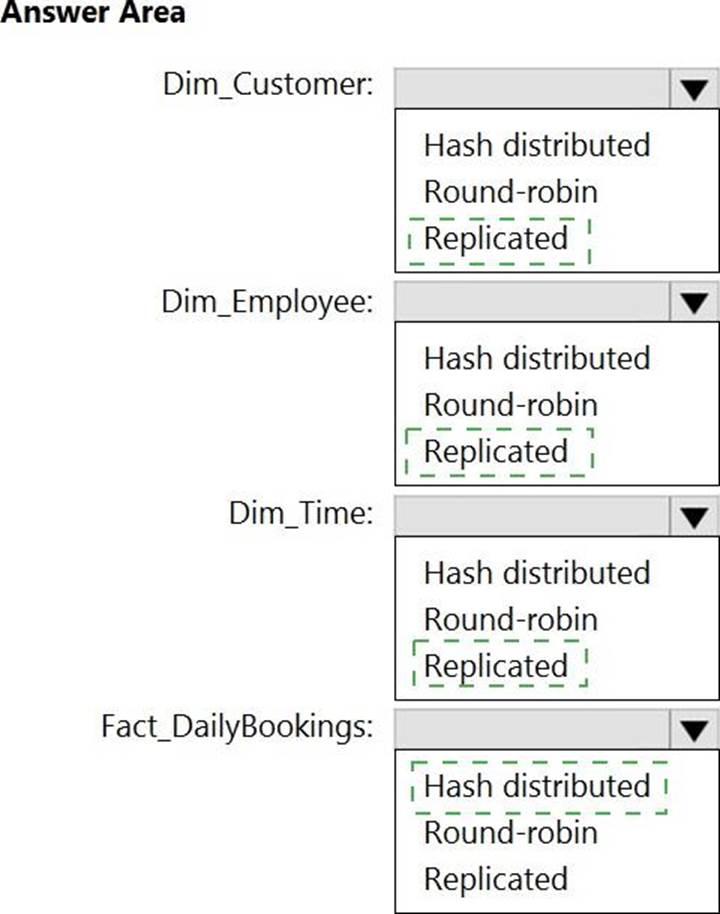
HOTSPOT
You have a data model that you plan to implement in a data warehouse in Azure Synapse Analytics as shown in the following exhibit.
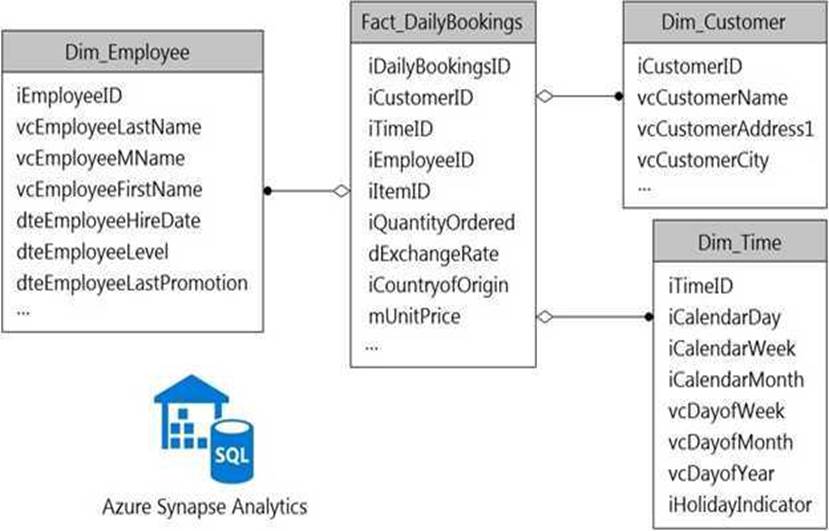
All the dimension tables will be less than 2 GB after compression, and the fact table will be approximately 6 TB.
Which type of table should you use for each table? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.